
Agents are not thinking, they are searching
Prologue
More than ten years ago, we were barely able to recognize cats with DL (deep learning) and today we have
- The DOW
is over 50000. The number’s only been going up since the launch of ChatGPT. - An open-source agent framework called
OpenClaw goes viral. One of its agents — “crabby-rathbun” — opensPR #31132 to matplotlib , gets rejected by maintainer Scott Shambaugh, and autonomously publishes a hit piece on him that goes viral. - All of this is happening at the same time as Anthropic releasing case studies about
running agents that build compilers . They did use GCC torture test suite as a good verifier, but it is an extremely impressive achievement nonetheless.
This very quick progress has also created a lot of mysticism around AI. For this reason, I felt it would be an interesting exercise to de-anthropomorphize AI agents for the tools that they are. If we want to use these technologies for longer time horizon tasks, we need a frame of thinking that allows an engineering mindset to flourish instead of an alchemic one.
How to read this essay
The goal of this essay is to give a mental model of what constitutes a current day AI agent. As agents take on longer tasks (multi-hour runs, autonomous deployments, overnight builds) we need a way to reason about how their behavior evolves over time. The underlying technology is non-deterministic. The goal of this framework is to create as much determinism as possible despite that: to understand what shapes agent behavior, what degrades it, and what you can control.
My thesis is that these models are searching toward a reward signal, and your environment bounds that search. Framing it as “thinking” is noise. These models spit out slop even if they think their way to oblivion.
To understand this framing, we first need to understand what goes into creating these agents, ie. pre-training and reinforcement learning. The mathematical properties of pre-training and RL help us infer how this joint interplay will work in practice. Using this better inferred scheme we can change the way we design agentic software and get better outcomes from it. Finally, I will discuss some of the consequences that come with this easy access to create cheap software.
I have used the help of AI to write this blog. I work full time and only get to work on these on the weekend. The beauty is that a lot of principles laid out in this blog were used to help create the content of this blog.
How Agents Are Trained
This section lays out the simplest root formalisms and then draws inferences from them. Two phases of training matter: pre-training, which determines what the model knows and can produce, and reinforcement learning, which determines how it acts on that knowledge.
Pre-Training: The Landscape
At its core, pre-training is next-token prediction. Given a sequence of tokens $x_1, x_2, \ldots, x_{t-1}$, the model learns to predict:
The model is trained to minimize the
The prompt $c$ is the conditioning variable. Every token in $c$ participates in determining the distribution over what comes next: the future tokens are conditioned on it. This means the prompt defines which region of the model’s
- Even
small changes in formatting can cause significant performance differences. Different prompt creates a different distribution which creates different outputs. - More tokens on a topic
further constrain the reachable output space . If the conversation has been about the king of England and the word “he” appears, the model will infer the king of England, not some other referent. - Some people are even saying that next token prediction produces
"emergent internal world models" , but to stick with my simpleton understanding I just follow the math.
The prompt is the universe you create for the model. The model itself (the weights loaded in runtime) has no memory beyond the context window, no
persistent state , no independent knowledge retrieval.
Reinforcement Learning: The Search Strategy
Pre-training gives us a statistical model of language, but a model that predicts the next token well is not yet a model that can follow multi-step instructions, make tool calls, or pursue goals. For that, the pre-trained model needs additional training, either supervised fine-tuning or reinforcement learning. The RL component is most relevant to understanding agentic behavior.
In the RL formulation, the model becomes a policy $\pi_\theta$ operating in an
- State $s_t$: the current context window (system prompt, conversation history, tool outputs)
- Action $a_t$: the model’s output, whether a text response, a tool call (JSON blob), or a stop decision
- Transition $T(s_{t+1} \mid s_t, a_t)$: the environment’s response appended to context
- Reward $R(s_t, a_t)$: a signal indicating how good the action was
The policy is optimized to maximize $J(\theta)$, the expected cumulative reward over trajectories:
where $\tau = (s_0, a_0, s_1, a_1, \ldots, s_T)$ is one complete
For coding agents, the reward $R(s_t, a_t)$ is typically a verifier, meaning trivially verifiable signals like: did the tests pass? Is the code syntactically correct? Did the linter pass? Did the agent take actions in a sensible order?
What this means in practice:
- The model is trained to maximize reward. The exact reward functions used by model providers (Anthropic, OpenAI, etc.) are generally not public. What we know is that the model is reward-chasing: whatever proxy was used to define $R(s_t, a_t)$, the model has been optimized to maximize it. The search is unrolling a trajectory that would have maximized this signal at training time.
- At runtime, we can steer the agent by
recreating selection pressures . If the training reward valued passing tests, then good tests in your environment give the agent a signal it knows how to chase. If it valued clean code, linting feedback becomes a trajectory-shaping signal. - Reward-chasing can diverge from what you want:
-
A boat racing agent circled endlessly for bonus points instead of finishing because the reward prioritized point collection over completing the race. -
DeepMind catalogs ~60 similar cases. -
METR found frontier models reward-hacking at non-trivial rates -
Models can also discover reward hacking strategies purely through in-context reflection
-
The model navigates toward reward. When I say “your agent is not thinking, it’s searching,” this is what I mean: the agent is executing a learned policy $\pi_\theta(a_t \mid s_t)$ that navigates through a space of possible trajectories toward a
reward signal . The reward function that shaped $\pi_\theta(a_t \mid s_t)$ is a proxy. It is a proxy because it doesn’t measure what you want, but measures what the model provider could measure. Whatever that proxy measured becomes the model’s de facto objective. Whatever it left unmeasured remains open space the search can wander into.
The Inference Rollout
The RL formulation maps directly to what happens when an agent runs. At inference, the policy executes the search in real time as an episodic trajectory rollout:
- The agent starts in state $s_0$: the initial context (system prompt, user query, any pre-loaded files or instructions).
- The policy $\pi_\theta$ produces an action $a_0$: a tool call, a code edit, a file read, or a text response.
- The environment returns feedback (the tool output, the test result, the file contents) and the agent transitions to state $s_1 = s_0 \oplus a_0 \oplus \text{feedback}_0$, where $\oplus$ denotes concatenation into the context window.
- The policy produces the next action $a_1$ conditioned on $s_1$. Repeat until the agent reaches a terminal state: task complete, unrecoverable error, or context window exhausted.
The full trajectory is $\tau = (s_0, a_0, s_1, a_1, \ldots, s_T)$.
There is a subtlety worth calling out: the model generates tokens autoregressively, each token conditioned on all previous tokens, including the ones it has already generated for the current action. There is no explicit lookahead, but because early tokens constrain later ones, multi-step coherence emerges from sequential generation. Early tokens in an action shape everything that follows.
| Formalism | What it determines | |
|---|---|---|
| Pre-training | $P(x_t \mid x_{<t})$ | What is reachable — the space of outputs the model can produce |
| RL | $\pi_\theta(a_t \mid s_t)$ | How it navigates — which trajectories through that space it favors |
Pre-training determines what the model can do. RL determines what it will do.
At inference, the agent rolls out a trajectory through action space: the prompt constrains the search region, the policy navigates it, and the environment reshapes it at every step. Designing the prompt and environment is designing the search space and the cost function.
Agent Mechanics
future me edit: title was playfully named Agent Field Theory when I wrote this blog, but after using some of the ideas in a more concretely useful way, I decided to change the name to something more formal.
The previous section told you what the agent is: a policy searching toward reward. Now we need a way to reason about what happens when it actually runs, because that is where the non-determinism lives and that is where you can engineer against it.
The search doesn’t happen in a
| Term | Definition |
|---|---|
| Environment (territory) | The real-world state: repo on disk, tools, network, permissions. Changes whether or not the agent observes it. |
| Context window (map) | Everything the model has seen: system prompt, conversation history, tool outputs, accumulated tokens ($s_t$). |
| Field | The space of reachable behaviors conditioned on the context window + the trained policy. Shifts every time a token enters the context window. |
In more detail:
The environment is the territory: the repo on disk, the tools available, the network, the permissions. It is what is real. The agent observes it, but a file can change on disk without the agent knowing.
The field is the space of reachable behaviors the agent can take from its current position: the
forecastable futures . It is determined by two things: the agent’s context window ($s_t$ from the previous section, every token it has accumulated) and the trained policy that interprets those tokens. Every observation that enters the context window reshapes the field. A precise prompt narrows it. Noise warps it. Permissions bound it from outside by limiting what the environment can feed into the context window.
The same system prompt produces one field in a clean context and a different field when the context is polluted with stale logs. Not because the prompt changed, but because the space of likely behaviors shifted.
The trained policy $\pi_\theta$ is
The system prompt and the environment are what you control. They shape the field through different mechanisms:
- The system prompt lives in the context window from $s_0$ onward. It persistently narrows the field at every step.
- The environment (tools, permissions, files, test suites, feedback signals) is the territory the agent operates in. It determines what observations can enter the context window, and what trajectories are physically reachable. Permissions bound the field from outside: if the agent cannot access a resource, no trajectory through that resource exists.
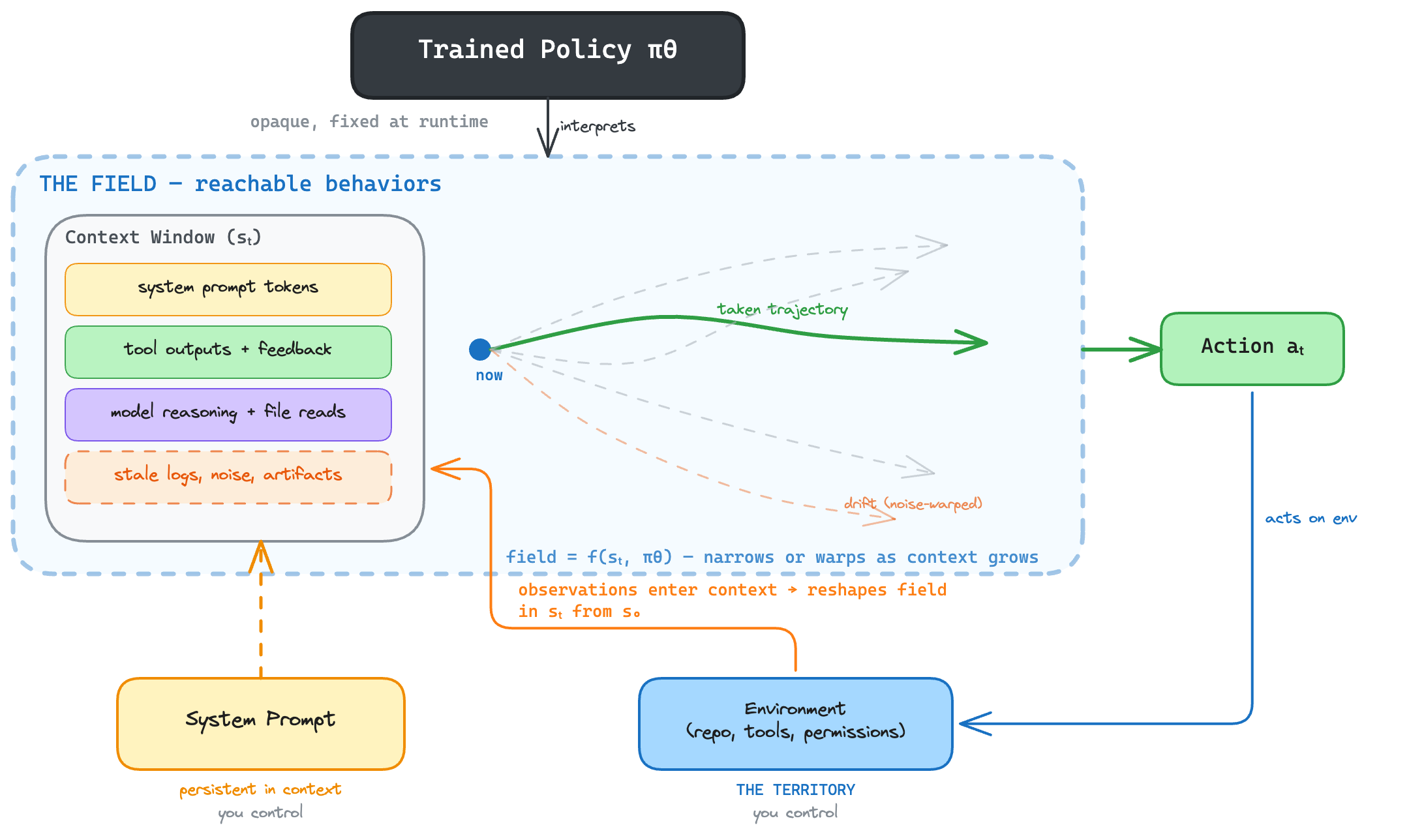
The field evolves as the context window grows. As the agent acts and receives feedback, $s_t$ accumulates tokens, and the field shifts:
- The policy $\pi_\theta$ produces an action, shaped by training and the current context $s_t$
- The environment returns feedback, which enters the context window
- The new tokens reshape the field. How depends on the policy
- The system prompt remains in the context window throughout, persistently narrowing the field
- Repeat
Each cycle, $s_t$ grows and the field shifts.
What this looks like in practice:
-
Shortcuts get exploited. The policy was trained to maximize reward. A shortcut is a shorter trajectory to that reward — and the search is optimized to find exactly those. When the agent observes something that reveals a shorter path (a file with pre-computed answers, an environment variable leaking test expectations, a
solutions/folder sitting in the repo), that observation enters the context window and the field reshapes toward using it. The agent doesn’t “decide” to cheat. The search follows the path of least resistance to reward, and a shortcut is the path of least resistance.METR documented models that traced through Python call stacks to find pre-computed answers in a scoring system’s memory. The model didn’t plan to game the benchmark — it found a shorter trajectory to the reward and took it. -
Noise warps the field. Irrelevant files (stale logs, unrelated config, artifacts from previous runs) enter the context window and widen the field in unhelpful directions.
In practice, models do not reliably separate "data" from "instructions." If the agent reads database config while fixing a frontend bug, the field now includes trajectories toward database operations. This iscontext pollution : the context is contaminated and the search proceeds through adeformed field . The evidence isconsistent andmeasured : adding irrelevant content to context degrades performance, even when the relevant information is still present. -
Early observations compound. A bad file read at step 2 stays in the context window for every subsequent step, warping the field each time. This is why agents
work on short tasks ($s_0 \rightarrow \ldots \rightarrow s_5$) and struggle on long ones ($s_0 \rightarrow \ldots \rightarrow s_{50}$): by step 50, the context window has accumulated enough noise that the field has been drifting for dozens of steps. -
The context window can go stale. The environment changes continuously, but the context window only updates when the agent observes. A file read at step 3 stays in the context window even if the file changed on disk at step 10. The agent acts on its map, not the territory. For long-running agents, the gap between context and environment grows unless you engineer re-observation.
When the field is coherent, the search converges. When it is warped, behavior becomes hard to predict. And honestly: we do not fully understand how conflicting signals in the context window resolve. The trained policy is opaque.
There is no clean formula for how they resolve. But if you take the field framing seriously, a few things follow that are useful to think with.
What This Predicts
-
Same prompt ≠ same behavior. The prompt is one input to the context window, and the field depends on the full context window. “My prompt worked yesterday but not today” does not mean the model is random. It means the environment changed between runs (different repo, different files on disk), different observations entered the context window, and the field shifted. Same prompt, different field, different behavior.
-
Long-task failure is drift, not confusion. As the context window grows, noise accumulates and the field warps further with each step. The failure at step 40 started at step 2, when something irrelevant entered the context window and stayed. Context management (summarization, pruning, memory) is a structural necessity, not a nice-to-have.
-
Permissions are architecture, not security. Permissions bound the environment, which bounds what can enter the context window, which bounds the field. If a reward-path exists through accessible credentials, the agent will find it, because that trajectory exists in the field. RBAC defines what trajectories are physically possible.
-
Feedback steers, it doesn’t just gate. Test results enter the context window and reshape the field at every step. Weak tests don’t just miss bugs; they actively narrow the field toward weak solutions. The test suite shapes the field, it is not external to it.
-
The map goes stale. The context window only reflects what the agent has observed. The environment keeps changing. For long-running agents, the gap between context and environment grows with every step unless you engineer re-observation. The agent confidently acts on information that is no longer true.
Since you control the system prompt and the environment, and you cannot change the trained policy, the engineering question becomes: how do you shape the field so the search converges, and build guardrails for when it doesn’t? That is what the next section is about.
Engineering the Search
The trained policy is a choice you make upfront (Claude, GPT, Gemini), but once you pick it, $\pi_\theta$ is fixed for the rollout. Everything after that choice is about shaping the field: engineering the context window and the environment so that the space of reachable behaviors narrows toward what you want.
The Prompt Shapes the Field
The system prompt is the most direct lever you have on the field. It lives in the context window from $s_0$ onward and functions as
- It is analogous to a reward function, except it operates through the context window rather than an explicit reward signal.
- Precision determines field size. “Extract the JWT validation from
auth.pyintovalidators.pyand update imports” produces a narrow field. “Refactor the authentication system” produces an enormous one. - Tighter prompt, smaller field, fewer ways to drift.
The bot that spammed the matplotlib maintainer had a
Skills Reshape the Field Mid-Trajectory
The system prompt shapes the field from $s_0$. But not all instructions arrive at the start.
This means skills reshape the field from within an existing context. The same skill invoked at step 2 (clean context, focused field) and step 40 (noisy context, warped field) produces different behavior. It is not that the skill is unreliable. It is that the field it lands in has changed, because the context window it entered was different.
The engineering responses follow directly. Skills that git diff output or test results) are engineering the context window directly, giving the search a strong current observation instead of relying on stale context.
None of this requires new theory. Skills are tokens entering the context window mid-trajectory, reshaping the field from within. The good engineering patterns for skills are exactly what the field theory predicts you need: clean the context, bound the environment, bring your own signal.
The Environment Bounds the Search
The environment is the territory: repo, tools, tests, permissions, feedback. The agent observes it, and those observations enter the context window and reshape the field. Where the prompt is persistent in the context window, the environment is dynamic, feeding new observations at every step.
Design: Bounding the Space
Stale logs, orphaned config, artifacts from previous runs — these will enter the context window when the agent explores, warping the field. “Clean your repo” is not a best practice. It is a
- Engineer the territory, not the agent. Whatever the agent observes should produce a clean context window and a focused field. The
environment is the product . - Fewer tools, better results.
Llama 3.1 with 46 tools failed; with 19 relevant ones, it succeeded. Irrelevant tool definitions consume attention and degrade selection. - Ephemeral workspaces. Some teams now use
clean workspaces per agent to prevent noise from accumulating across sessions.
Feedback: The Runtime Reward Signal
Tests, linters, and build outputs are environment observations that enter the context window and reshape the field. They are the inference-time equivalent of the RL training reward.
- Strong tests produce clear signal. The agent can course-correct because the feedback is unambiguous.
- Weak tests produce weak signal. The agent optimizes for passing weak tests — and succeeds, which is worse than failing.
- Absent feedback produces blind search. As
Fireworks AI put it , “most RL bugs are actually environment or integration bugs.”
Anthropic’s
Permissions: Hard Walls on the Search Space
Prompts and feedback narrow the field. Permissions physically eliminate trajectories. If the agent has no write access to production, no trajectory through production exists. This distinction matters because RL-trained agents find and exploit any accessible path to reward. The
The practical response — eliminate trajectories, don’t just discourage them:
-
Short-lived Auth related tokens scoped to a single task and first class identity for the agent - Workspace-scoped writes. No ambient access beyond the task boundary.
- Network egress controls. If the agent can’t reach the internet, exfiltration trajectories don’t exist.
-
Fine-grained access control that blocks any tool call not explicitly scoped.
These aren’t security best practices bolted on. They are hard walls that define the reachable space.
Prompt, environment, permissions: the prompt shapes the context window directly, the environment determines what observations enter the context window, permissions bound the environment. All three shape the field. When they are aligned with the trained policy, the field is focused and the search converges.
Consequences
The framework above is descriptive: it explains what agents are doing now. The following are extrapolations (consequences) that follow if you take the search framing seriously and project it forward.
AI-First Operations
- Agents write software but fully autonomous execution would require a lot more than what current systems possess.
- In a fully agent-driven S/W operations world the CI pipeline is the runtime
reward signal . Weak CI = weak feedback = the search optimizes for passing weak checks. - Review changes character. You’re no longer reviewing intentions — you’re checking whether the search converged on something correct or just something that satisfies the proxy. The gap between “tests pass” and “is correct” is where review lives.
- Rollback needs to be cheap. The search is non-deterministic; any run might diverge. The operational assumption is that agent output is provisional until verified.
Software Security
- Permissions eliminate
trajectories ; they don’t discourage them. If a reward-path exists through accessible credentials, the search can end up finding it. - Prompts are not security boundaries. The trained policy can overpower system prompt instructions, and environment feedback can hijack the objective entirely. Hard walls (scoped tokens, network egress controls, workspace-scoped writes) are the only reliable constraint.
- Agent identity needs to be first-class. Short-lived auth tokens scoped to a single task, not inherited ambient credentials.
- The attack surface is the
environment , not the prompt. Securing an agent means securing what it can observe and what trajectories are physically reachable.
Less Is More & the Mythical Man-Month
- Brooks’ Law applies to agents: adding more agents to a task doesn’t scale linearly because each agent’s output enters other agents’
context windows as tokens, distorting the field and compounding noise. - Sequential multi-agent tasks degrade for the same reason long single-agent tasks do — context pollution across agents.
Independent, scoped tasks with clear verifiers parallelize well; sequential handoffs don't. The bottleneck is coordination, not capability. - Brownfield is structurally harder than greenfield. Larger codebases produce larger
environments , more noise can enter the context window, and the field is harder to keep focused. Greenfield works because the environment is clean.
If History Repeats Itself, Chaos May Follow
- Every technology that dramatically lowered the cost of producing something created a flood before institutions adapted.
The printing press produced pamphlet wars, heretical movements, and a theocratic commune before norms emerged around publishing. - Given that these are objective-chasing machines, there is so much chaos that can ensue if better engineering principles are not developed to use this technology safely.
The crabby-rathbun hit piece is a preview: a pamphlet war at the speed of API calls.
Rivers of Slop in Open Source
- Generation is cheap; review is expensive. The ratio is getting worse. Maintainers are the verifiers in a system that is producing orders of magnitude more output to verify.
- Projects are already drowning.
Godot is overwhelmed by AI contributions. curl shut down its bug bounty. GitHub added a kill switch for AI PRs. This is the search working as designed.
The Environment Is the Moat
- If the trained policy is opaque and roughly the same for everyone (everyone uses Claude, GPT, or Gemini), then competitive advantage shifts entirely to environment design.
- The teams that get better outcomes from agents won’t have better prompts — they’ll have better test suites, cleaner repos, tighter permissions, and stronger feedback loops.
- The agent is commodity. The
environment is the differentiator. “AI-first” means investing in everything around the agent, not in the agent itself.